8月28日,腾讯混元今日宣布开源端到端视频音效生成模型Hunyuan-Foley。借助这一模型,用户仅需输入视频与文字,就能轻松为视频匹配到电影级别的音效,填补了AI视频在音频生成方面的空白。
8月28日,腾讯混元今日宣布开源端到端视频音效生成模型Hunyuan-Foley。借助这一模型,用户仅需输入视频与文字,就能轻松为视频匹配到电影级别的音效,填补了AI视频在音频生成方面的空白。
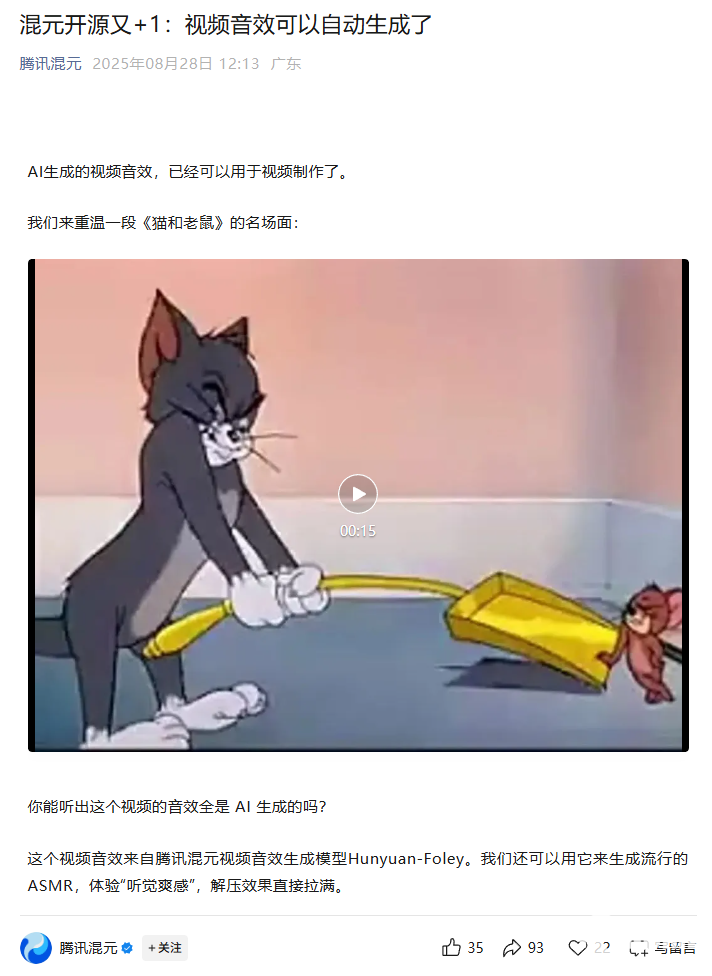
据官方介绍,HunyuanVideo-Foley打破了AI生成视频“有画无声”的局限,真正做到“看懂画面、读懂文字、配准声音”,为用户带来沉浸式视听感受。该模型应用场景广泛,短视频创作、电影制作、广告创意、游戏开发等领域都能借助它提升作品质量。
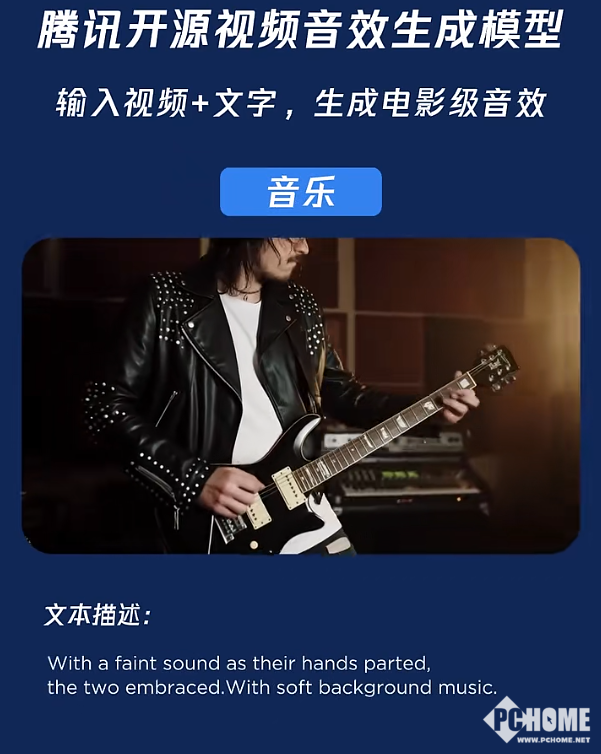
为训练该模型,混元团队构建了一套全面的数据处理流程,对收集到的音视频数据进行自动化标注与过滤,进而打造出约10万小时级别的高质量TV2A数据集。这为模型赋予了强大的泛化能力,使其能够在复杂视频条件下,生成与画面、语义精准匹配的高质量音频,包括音效与背景音乐,显著增强视频的真实感与沉浸感。












